UNIT 1: SOFTWARE
PROCESS AND PROJECT MANAGEMENT
PART –
A
1. Define
Software Engineering. [Nov – 2013]
Software
engineering is the systematic approach to develop and maintain a s software product in a cost
effective and efficient way.
2. What is Software?
Software
is nothing but a collection of computer programs that are related documents
that are indented to provide desired features, functionalities and better
performance.
3. What are
the Generic Framework Activities?
• Communication
• Planning
• Modeling
• Construction
• Deployment
4. What are the characteristics of the software?
1. Software is developed
or engineered; it is not manufactured in the classical sense.
2. Software does not
“wear out”.
3. Although the industry is
moving toward component-based construction, most software continues to be custom built.
5. What
are the various categories of software?
System
software, Application software, Engineering/Scientific software, embedded
software, Web Applications, Artificial Intelligence software.
6. Define
software process. List its activities. [May -2013]
Software
process is defined as the structured set of activities that are required to
develop the software system. The activities are
Ø
Specification
Ø
Design and implementation
Ø
Validation
Ø
Evolution
7. What
are the fundamental activities of a software process?
1. Specification,
2. Design and
implementation,
3. Validation
4. Evolution.
8. What are the umbrella activities of a
software process?
Software
project tracking and control, Risk
management, Software Quality Assurance, Formal Technical Reviews, Software
Configuration Management, Work product preparation and production, Reusability
management, Measurement.
9. Write the disadvantages of classic life cycle
model.
[i] Real projects rarely
follow sequential flow. Iteration always occurs and creates
problem.
[ii] Difficult for the
customer to state all requirements.
[iii] Working version of the
program is not available. So the customer must have patience.
10. What are the potential advantages
of adhering to the life cycle model of Software? [Nov -2012]
o
Easy to use.
o
Work well for projects where
requirements are very well understood.
o
Cost effectiveness.
11. ‘Software doesn’t wear out’.
Justify. [Nov-2013]
As the
time progress, the hardware components start deteriorating – they are subjected
to environment maladies such as dust, vibration, temperature etc., and at same
point of time they tend to breakdown.
But
software is no susceptible to the environment changes, software does not wear
out. The software works exactly the same way even after years it was first
developed unless any charges are introduced to it.
The
changes in the software may occur due to the changes in requirements.
12.
What is EVA?
Earned Value Analysis is a technique of performing
quantitative analysis of the software project. It provides a common value scale
for every task of software project. It acts as a measure for software project
progress.
13.
What is COCOMO model?
Constructive Cost Model is a cost model, which gives the
estimate of number of man-months it will take to develop the software product.
14. Define Risk. [Nov- 2013]
Risks are the possible problems that
might endanger the objectives of the project stakeholders. It is the
possibility of a negative or undesirable outcome. A risk is something that has
not happened yet and it may never happen; it is a potential problem.
15. What is meant by risk management?
Risk management is an
activity in which risks in the software projects are identified.
16.
What is meant by software project scheduling?
Software project
scheduling is an activity that distributes estimated effort across the planned
project duration by allocating the effort to specified software engineering
tasks.
17. What is meant by software cost estimation?
The software cost
estimation is the process of predicting the resources required for software
development process.
18. What is the difference between the “Known
Risks” and Predictable Risks” ?
Known Risks :-
That can be uncovered after careful evaluation of the project plan, the
business, and technical environment in
which the product is being developed.
• Example: Unrealistic delivery rate
Predictable Risks: -
Extrapolated
from past project experience
Example: Staff turnover.
PART B
1.
1 Explain the life cycle model.[Nov/Dec 2014,2013,2010,201]
-Waterfall model
- Incremental process
model.
- Evolutionary
process model
2. Explain
iterative waterfall and spiral model for software life cycle and various
activities in each phase. [Nov/Dec 2014,2013]
Iterative waterfall model
Requirement gathering phase in
which all requirements are identified. · The design phase is responsible for
creating architectural view of the software.
The implementation phase in which the software design is transformed
into coding. · Testing is a kind of phase in which the developed software
component is fully tested. Maintenance
is an activity by which the software product can be maintained.
Requirements
Design
Implementation
Testing
Maintenance
SPIRAL MODEL
· The spiral model is divided into number of frame works. These
frameworks are denoted by task regions. · Usually there are six task regions.
In spiral model project entry point axis is defined.
· The task regions are:
Customer communication
Planning
Risk analysis.
Construct and release.
Customer evaluation.
Drawbacks
· It is based on customer communication.
· It demands considerable risk assessment.
UNIT 2: REQUIREMENTS ANALAYSIS AND
SPECFICATION
PART A
1.
What is requirement engineering?
Requirement engineering is the process of establishing the
services that the customer requires from the system and the constraints under
which it operates and is
developed.
2.
What are the characteristics of SRS?
i. Correct – The SRS should be made up to date when appropriate
requirements are identified.
ii. Unambiguous – When the requirements are correctly understood then
only it is possible to write unambiguous software.
iii. Complete – To make SRS complete, it should be specified what a
software designer wants to create software.
iv. Consistent – It should be consistent with reference to the
functionalities identified.
v. Specific – The requirements should be mentioned specifically.
vi. Traceable – What is the need for mentioned requirement? This should
be correctly identified.
3.
What are the various types of traceability in software engineering?
i. Source
traceability – These are
basically the links from requirement to stakeholders who propose these
requirements.
ii. Requirements
traceability – These are links
between dependant requirements.
iii. Design
traceability – These are links
from requirements to design.
4. What are the Requirements Engineering Process
Functions?
• Inception
• Elicitation
• Elaboration
• Negotiation
• Specification
• Validation
• Management
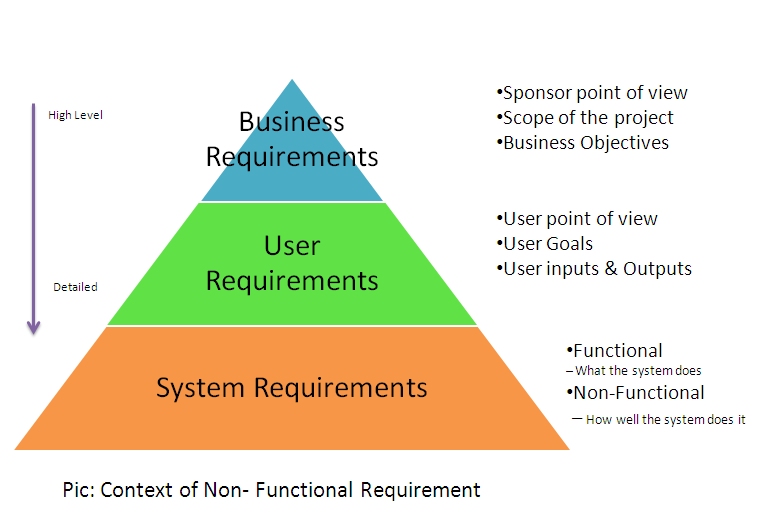
5. Define Functional
requirements.
These are statements of services the system
should provide, how the system should react to particular inputs, and how the
system should behave in particular situations. In some cases, the functional
requirements may also explicitly state what the system should not do.
6. Define
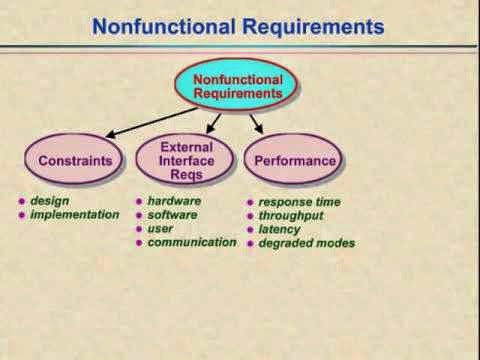
Non-functional requirements.
These are constraints on the services or
functions offered by the system. They include timing constraints, constraints
on the development process, and constraints imposed by standards.
Non-functional requirements often apply to the system as a whole, rather than
individual system features or services.
7. Name the
metrics for specifying non-functional requirements. [Nov- 2011]
|
Property
|
Measure
|
|
Speed
|
Processed transactions /
second user / event response time
|
|
Size
|
Mbytes , Number of ROM chips
|
|
Ease of use
|
Training time, Number of help
frames
|
|
Reliability
|
Mean time to failure,
Probability of unavailability
|
|
Robustness
|
Time to restart after
failure, Percentage of events causing failure, Probability of data corruption
on failure
|
|
Portability
|
Percentage of target
dependent statements, Number of target systems.
|
8. “An SRS is
traceable. Comment. [Nov- 2012]
There may be chances of having new requirements
during development of the software. Traceability is concerned with relationship
between requirements their sources and the system design. Thus changes in
requirement is manageable is SRS is traceable.
9. Define User
Requirements.
User requirements are statements, in a natural
language plus diagrams, of what services the system is expected to provide to
system users and the constraints under which it must operate.
10. Define system
requirements.
System requirements are more detailed
descriptions of the software system’s functions, services, and operational
constraints. The system requirements document [sometimes called a functional
specification] should define exactly what is to be implemented. It may be part
of the contract between the system buyer and the software developers.
11. What is software requirements document?
The software requirements document is an agreed
statement of the system requirements. It should be organized so that both
system customers and software developers can use it.
12. Write the structure of a requirements
document.
1. Preface
2. Introduction
3. Glossary
4. User requirements definition
5. System architecture
6. System requirements specification
7. System models
8. System evolution
9. Appendices
10. Index
13. Define
feasibility study.
A feasibility study is a short, focused study
that should take place early in the Requirements Engineering process. It should
answer three key questions: a] does the system contributes to the overall
objectives of the organization? b] Can the system be implemented within
schedule and budget using current technology? And c] Can the system is
integrated with other systems that are used?
If the answer to any of these questions is no,
you should probably no to go ahead with the project.
14. Define Data
dictionary. [May-2013].
The data dictionary can be defined as an
organized collection of all the data elements of the system with precise and
rigorous definitions so that user and system analyst will have a common
understanding of inputs, outputs, components of stores and intermediate
calculations.
15. Define Petri
Nets analysis.
§
First introduced by Carl Adam Petri in 1962.
§
A diagrammatic tool to model concurrency and
synchronization in distributed systems.
§
Very similar to State Transition Diagrams.
§
Used as a visual communication aid to model the
system behavior.
§
Based on strong mathematical foundation.
16. Distinguish between the
terms inception, elicitation and elaboration with reference to requirements. [Nov
– 2012]
Requirements elicitation which involves asking the
customer user, what the objectives of system, what is to be accomplished? How
the system [or] product fits into the needs of the business and how the system
[or] product is to be used on a day-to-day basis.
The goal of the inception phase is to establish a
business case for the system. We should identify all external entities that
will interact with the system and define these interactions.
The goals of the elaboration phase are to develop an understanding
of the problem domain, establish an architectural framework for the system, to
develop the project plan and identify key project risks.
17. What are the elements of Analysis model?
i. Data Dictionary
ii. Entity Relationship Diagram
iii. Data Flow Diagram
iv. State Transition Diagram
v. Control Specification
vi. Process specification
PART B
1. Explain Feasibility Study.[Nov / Dec 2013]
-
Information Assessment
-
Information Collection
-
Report Writing
2. Explain Requirements Elicitation and
Analysis.[April/May 2011]
-
Problem of scope
-
Problem of understanding
-
Problem of volatility
-
Problem of potential factors.
3. Discuss about Requirements Validation.
[April/May 2011]
-
Validity checks
-
Consistency checks
-
Completeness checks
-
Realism checks
-
Verifiability
4. Explain Requirements Management.[Nov/Dec 2012]
-
Enduring and Volatile requirements
-
Requirements Management Planning
-
Requirements Management
5. Write about Data dictionary.
-
Name of the data item
-
Aliases
-
Description
-
Related data items
-
Range of value
-
Data structure definition
-
Where used / How used
UNIT 3: SOFTWARE DESIGN
PART A
1. What are the elements of design model?
i. Data design
ii. Architectural design
iii. Interface design
iv. Component-level design
2. Define design
process.
Design process is a sequence of steps carried
through which the requirements are
translated
into a system or software model.
3. Draw the DFD notations for the following. [Nov
– 2011]
a] External Entity
4. List the principles of a good design. [Nov-2013]
i. The design process should not suffer from
“tunnel vision”.
ii. The design should be traceable to the
analysis model.
iii. The design should exhibit uniformity and
integration.
iv. Design is not coding.
v. The design should not reinvent the wheel.
5. What is the
design quality attributes ‘FURPS’ meant? [Nov-2012]
§
Functionality
§
Usability
§
Reliability
§
Performance
§
Supportability
6. What is a cohesive module?
A cohesive module performs only “one task” in
software procedure with little interaction with other modules. In other words
cohesive module performs only one thing.
7. What are the
different types of Cohesion?
i. Coincidentally cohesive –The
modules in which the set of tasks are related with each other loosely then such
modules are called coincidentally cohesive.
ii. Logically cohesive – A
module that performs the tasks that are logically related with each other is
called logically cohesive.
iii. Temporal cohesion – The
module in which the tasks need to be executed in some specific time span is
called temporal cohesive.
iv. Procedural cohesion – When
processing elements of a module are related with one another and must be
executed in some specific order then such module is called procedural cohesive.
v. Communicational cohesion – When
the processing elements of a module share the data then such module is called
communicational cohesive.
8. What is coupling?
Coupling is the measure of interconnection among
modules in a program structure. It depends on the interface complexity between
modules.
9. What are the
various types of coupling?
i. Data coupling – The data coupling is possible by parameter passing or data
interaction.
ii. Control coupling – The
modules share related control data in control coupling.
iii. Common coupling – The common data or a global data is shared among modules.
iv. Content coupling – Content coupling occurs when one module makes use of data or
control information maintained in another module.
10. What are the
common activities in design process?
i. System structuring – The
system is subdivided into principle subsystems components and communications
between these subsystems are identified.
ii. Control modeling – A
model of control relationships between different parts of the system is
established.
iii. Modular decomposition
– The identified subsystems are decomposed into modules.
11. Develop a CRC
model index card for a class “Account’ used in banking application.
Class Account
Class type Transaction
Class Characteristic: Tangible Permanent
Sequential Guarded
Responsibility Collaboration
Precedes Account Customer
Details Show
Current Balance
Withdraw Amount
Deposit Amount
12. What are the Basic Design principles of
Class-Based Components?
• Open-Closed
Principle [OCP]
• Liskov
Substitution Principle[LSP]
• Dependency
Inversion Principle[DIP]
• Interface
Segregation Principle[ISP]
• Release Reuse
Equivalency Principle[REP]
• Common Closure Principle[CCP]
• Common Reuse
Principle[CRP]
13. What are the important roles of Conventional
component within the software Architecture?
•Control Component: that coordinates
invocation of all other problem domain.
• Problem Domain Component: That implement Complete or Partial
function required by customer
• Infrastructure Component: That responsible for functions that
support processing required in problem domain.
14. What are the Different types of Design Model?
• Process Dimension:
Indicate evolution of Design model as design tasks executed as part of software process
• Abstraction Dimension: Represent
level of detail as each element of analysis model is transformed into design
equivalent.
15. List out the Different elements of Design
Model?
Data Design Elements
Architectural Design Elements
Interface Design Elements
Component Level Design Elements
Deployment Level Design Elements
16. What is the Objective of
Architectural Design?
Model
overall software structure by representing component interfaces, dependencies
and
relationships and interactions.
17. Define the terms in
Software Designing: [Nov – 2014]
[a] Abstraction :
1. Highest Level :
Solution is stated in broad term using language of
problem environment
2. Lower Level : More detailed
description of solution is provided
[b] Modularity:
Software is
divided into separately named and addressable components,
called Modules that are integrated to satisfy problem requirements.
PART B
1.
Explain the modular design with neat diagrams.
-
Cohesion
-
Coupling
2.
List out design heuristics for
effective modular design.[Nov/Dec 2014]
-
Modular Decomposability
-
Modular Composability
-
Modular Understandability
-
Modular Continuity
-
Modular Protection
3.
Write short notes on User Interface Design. [May/June 2013]
-
User Interface Design
principles.
-
Interface design Models
-
Interface design process
4. Explain the design principles.[April/May 2011]
· The design process should not suffer from tunnel vision.
· The design should be traceable to the analysis model.
· Design should not reinvent the wheel.
· The design should minimize the intellectual distance between the
software and problem as it exists in the real world.
· The design should be structured to degrade gently, even when
aberrant data, events or operating conditions are encountered.
· Design is not coding, coding is not design.
· The design should be assessed for quality as it is being created,
not after the fact.· The design should be reviewed to minimize conceptual
[semantic] errors.
UNIT 4: TESTING
AND IMPLEMENTATION
PART A
1.
Define testing
Testing is a process of executing
a program with the intent of finding of an error.
2.
Why is testing important?
Reviews and other SQA activities can
and do uncover errors, but they are not sufficient. Every time the program is
executed, the customer tests it. Therefore, we have to execute the program with
the specific intend of finding and removing all errors. Inorder to find the highest
possible number of errors, test must be conducted systematically.
3.
What are the steps of testing?
Software is tested from two different
perspectives:
1. Internal program logic is
exercised using “White-box”, test case design techniques.
2. Software requirements are
exercised using “Black-box”, test case design techniques.
4.
Mention the attributes of a good test [nov/dec2010]
The following are the attributes of
good test.
1. A good test has a
high probability of finding error.
2. Good test is not
redundant.
3. A good test should
be “best of breed”
4. A good test should
be neither too simple nor too complex.
5.
What is Black box testing?[may/june 2013]
Black
box testing is a test case design method that focuses on the functional
requirements of the Software. This is otherwise called as functional testing.
6. What is White-box testing?
White-box testing is the test
case design method that uses the control structure of the procedural design to
Derive test class. It is otherwise called as structural testing.
7. Mention of advantage and disadvantages of
White-box Testing?
Advantage:
1. Software’s Structure logic
can be tested.
Disadvantages:
1.
Doesn’t ensure that user requirements are met.
2.Its test may not mimic real-world
situations.
8. Mention the advantage and disadvantage
Black-box Testing?
Advantages:
Simulates
actual system usage.
Makes no
system structure assumption.
Disadvantages:
Potential of missing logical errors in software.
Possibility of
redundant testing
9. Diffrentiate Black box and
White-box Testing.
Black-box
Testing:
1.No knowledge of the internal
logic of the system is used to delevope test case.
2 tend to uncover error that
occur in implementing requirements or design specification.
3. Uses Validation techniques
4.Examples Include unit testing,
integration testing, system testing, acceptance testing.
5. Apply during later stages of
testing
White-box Testing:
1.
Knowledge of internal logic of the system is used to develop test cases.
2.
tends to uncover errors that occur during coding of the program
3.
Use verification techniques.
4.
Examples include Feasibility reviews, requirements reviews.
5.
Perform early in testing process.
` 10. Mention some of the black-box
testing techniques?
Graph-based testing methods,
Equivalences partitioning, boundary value analysis, comparison testing Orthogonal array testing
11. Mention some of the White-box testing techniques?
Basis path
testing, loop testing, data flow testing and conditional testing.
12. What is condition testing?
Condition testing is a test case
design method that exercises logical conditions in a program module.This method
focuses on testing each condition in the program.
13. Mention the Advantage of condition
testing?
a.)
Measurement of test coverage of a condition is simple.
b.) The test coverage of condition in a
program provides guidance for the generation of
Additional
test for the program.
14. What is meant by data flow
testing?[may/june 2014]
The data flow testing method
select test path of a program according to location of definition and uses of
variables in program.
15. Mention the advantages of condition
testing.
a)
Measurement of test coverage of a condition is simple.
b)
The test coverage of conditions in a program provides guidance for the
generation of additional tests for the program.
.
16. What is boundary value analysis?
Boundary
value analysis is a test case design technique that leads to a selection of
test cases that exercise bounding values. This technique has been developed for
the reason that a greater number of errors tend to occur at the boundaries of
the input domain rather than in the center.
17. When is
orthogonal array testing applicable?
Orthogonal
array testing can be applied to problems in which the input domain is relatively
small but too large to accommodate exhaustive testing. It is particularly
useful in finding errors associated with region faults within a software
component.
18. What is verification and
validation?[nov/dec 2010]
Verification refers to the set
of activities that ensure that software correctly implements a specific
function.
Validation refers to the set of
activities that ensure that the software that has been build is traceable to
customer requirements.
19. What is unit testing?
Unit testing
focuses verification on the smallest unit of software design-the software
component or module. Here the important control paths are tested to uncover
errors within the boundary of the module. The unit test is white-box oriented,
and the step can be conducted in parallel for multiple components.
20. What is alpha and beta tests?
Alpha test is the test that is
conducted at the developer’s site by a customer. Beta test is the test that is
conducted at one or more customer sites by the end-user of the software.
PART B
1.
Explain Cyclomatic Complexity and its Calculation
with example.
·
The number of tests to test all control
statements equals the cyclomatic complexity
·
Cyclomatic complexity equals number of conditions
in a program
·
Useful if used with care. Does
not imply adequacy of testing.
·
Although all paths are executed,
all combinations of paths are not executed.
123 4 6 5 7 while bottom <=
top if (elemArray [mid] == key (if (elemArray [mid]< key 8 9 bottom > top
Independent Paths:
1, 2, 3, 8, 9
1, 2, 3, 4, 6, 7, 2
1, 2, 3, 4, 5, 7, 2
1, 2, 3, 4, 6, 7, 2, 8, 9
Test cases should be derived so that all of these paths are
executed
A dynamic program analyser may be used to check that paths
have been executed.
Level N Level N Level N Level N Level N Level N–1 Level N–1
Level N–1 Testing sequence Test
Drivers Test drivers23
2. Explain the types of Black
Box testing in detail. [Nov/Dec 2014]
EQUIVALENCE PARTITIONING:
Equivalence partitioning is a
black-box testing method that divides the input domain of a program into
classes of data from which test cases can be derived. An ideal test case
single-handedly uncovers a class of errors (e.g., incorrect processing of all
character data) that might otherwise require many cases to be executed before
the general error is observed. Equivalence partitioning strives to define a
test case that uncovers classes of errors, thereby reducing the total number of
test cases that must be developed.
Test case design for equivalence partitioning is based on an
evaluation of equivalence classes for an input condition. Using concepts
introduced in the preceding section, if a set of objects can be linked by
relationships that are symmetric, transitive, and reflexive, an equivalence
class is present. An equivalence class represents a set of valid or
invalid states for input conditions. Typically, an input condition is a
specific numeric value, a range of values, a set of related values, or a
Boolean condition.
Equivalence classes may be defined according to the following
guidelines:
·
If an input condition specifies
a range, one valid and two invalid equivalence classes are defined.
·
If an input condition requires a
specific value, one valid and two invalid equivalence classes are
defined.
·
If an input condition specifies
a member of a set, one valid and one invalid equivalence class are
defined.
·
If an input condition is Boolean,
one valid and one invalid class are defined. As an example, consider data
maintained as part of an automated banking application.
The user can access the bank using a personal computer,
provide a six-digit password, and follow with a series of typed commands that
trigger various banking functions. During the log-on sequence, the software
supplied for the banking application accepts data in the form area code—blank
or three-digit number
·
Prefix — three-digit number not
beginning with 0 or 1
·
Suffix — four-digit number
·
Password — six digit
alphanumeric string
·
Commands — check, deposit, bill
pay, and the like
The input conditions associated with each data element for
the banking application can be specified as area code: Input condition, Boolean
— the area code may or may not be present.
Input Condition, range — values defined between 200
and 999, with specific exceptions.
Prefix: Input condition, range — specified value
>200
Input condition, value — four-digit length
Password: Input Condition, Boolean — a password may or
may not be present
Input Condition, value — six-character string
Command: Input Condition, set — containing commands noted
previously.
Applying the guidelines for the derivation of equivalence
classes, test cases for each input domain data item can be developed and
executed. Test cases are selected so that the largest numbers of attributes of
an equivalence class are exercised at once.
BOUNDARY VALUE ANALYSIS:
For reasons that are not completely clear, a greater number
of errors tends to occur at the boundaries of the input domain rather than in
the "center." It is for this reason that Boundary Value Analysis (BVA)
has been developed as a testing technique. Boundary value analysis leads to a
selection of test cases that exercise bounding values. Boundary value analysis
is a test case design technique that complements equivalence partitioning.
Rather than selecting any element of an equivalence class, BVA leads to the
selection of test cases at the "edges" of the class. Rather than
focusing solely on input conditions, BVA derives test cases from the output
domain as well
Guidelines for BVA are similar in many respects to those
provided for Equivalence
Partitioning:
If an input condition
specifies a range bounded by values a and b, test cases should be
designed with values a and b and just above and just below a and
b.
If an input condition specifies a number of
values, test cases should be developed that exercise the minimum and maximum
numbers. Values just above and below minimum and maximum are also tested.
Apply guidelines 1 and 2 to output conditions.
For example, assume that temperature vs. pressure table is required as output
from an engineering analysis program. Test cases should be designed to create
an output report that produces the maximum (and minimum) allowable number of
table entries.
If internal program data structures have
prescribed boundaries (e.g., an array has a defined limit of 100 entries), be
certain to design a test case to exercise the data structure at its boundary.
Most software engineers intuitively perform BVA to some degree. By applying
these guidelines, boundary testing will be more complete, thereby having a
higher likelihood for error detection.
3. Explain Unit testing and
Structural Testing in detail. [may/june 2011]
UNIT TESTING:
In unit testing the individual components are tested
independently to ensure their quantity. The focus is to uncover the errors in
design and implementation.
The various tests that are conducted during the unit test are
described as below.
·
Module interfaces are tested for
proper information flow in and out of the program.
·
Local data are examined to ensure
that integrity is maintained.
·
Boundary conditions are tested
to ensure that the module operates properly at boundary established to limit or
restrict processing.
·
All the basis (independent)
paths are tested for ensuring that all statements in the module have been
executed only once.
·
All error handling paths should
be tested.
a. Drivers and Stub software need to be developed to test
incomplete software. The driver is a program that accepts the test data and
prints the relevant results and the stub is a subprogram that uses the module
interfaces and performs the minimal data if required. This is given by
following figure.
b. The unit testing is simplified when a component with high
cohesion(with one function) is designed.in such a design the number of test
cases are less and one can easily predict or uncover errors.
STRUCTURAL TESTING:
White-box testing, sometimes
called glass-box testing is a test case design method that uses the
control structure of the procedural design to derive test cases. Using
white-box testing methods, the software engineer can derive test cases that (1)
guarantee that all independent paths within a module have been exercised at
least once,(2) exercise all logical decisions on their true and false sides,
(3) execute all loops at their boundaries and within their operational bounds,
and (4) exercise internal data structures to ensure their validity.
A reasonable question might be
posed at this juncture: "Why spend time and energy worrying about (and
testing) logical minutiae when we might better expend effort ensuring that
program requirements have been met?" Stated another way, why don’t we
spend all of our energy on black-box tests? The answer lies in the nature of
software defects
Logic errors and incorrect
assumptions are inversely proportional to the probability that a program path
will be executed. Errors tend to creep into our
work when we design and implement function, conditions, or controls that are
out of the mainstream. Everyday processing tends to be well understood, while
"special case" processing tends to fall into the cracks.
We often believe that a logical
path is not likely to be executed when, in fact, it may be executed on a
regular basis. The logical flow of a program is
sometimes counterintuitive, meaning that our unconscious assumptions about flow
of control and data may lead us to make design errors that are uncovered only
once path testing commences.
Typographical errors are random.
When a program is translated into programming
language source code, it is likely that some typing errors will occur. Many
will be uncovered by syntax and type checking mechanisms, but others may go
undetected until testing begins. It is as likely that a typo will exist on an
obscure logical path as on a mainstream path.
Basis Path Testing:
Basis path testing is a white-box testing technique first proposed by Tom
McCabe. The basis path method enables the test case designer to derive a
logical complexity measure of a procedural design and use this measure as a
guide for defining a basis set of execution paths. Test cases derived to
exercise the basis set re guaranteed to execute every statement in the program
at least one time during testing.
Flow Graph Notation:
Before the basis path method can be introduced, a simple notation
for the representation of control flow, called a flow graph (or program
graph) must be introduced. The flow graph depicts logical control flow
using the notation illustrated in Figure. Each structured construct has a
corresponding flow graph symbol.
To illustrate the use of a flow graph, we consider the
procedural design representation in Figure. Here, a flowchart is used to depict
program control structure
Figure maps the flowchart into a corresponding flow graph
(assuming that no compound conditions are contained in the decision diamonds of
the flowchart). Referring to Figure, each circle, called a flow graph node, represents
one or more procedural statements. A sequence of process boxes and a decision
diamond can map into a single node. The arrows on the flow graph, called edges
or links, represent flow of control and are analogous to flowchart
arrows. An edge must terminate at a node, even if the node does not represent
any procedural statements (e.g., see the symbol for the if-then-else construct).
Areas bounded by edges and nodes are called regions. When counting
regions, we include the area outside the graph as a region. When compound
conditions are encountered in a procedural design, the generation of a flow
graph becomes slightly more complicated. A compound condition occurs when one
or more Boolean operators (logical OR, AND, NAND, NOR) is present in a
conditional statement. Referring to Figure, the PDL segment translates into the
flow graph shown. Note that a separate node is created for each of the
conditions a and b in the statement IF a OR b. Each
node that contains a condition is called a predicate node and is
characterized by two or more edges emanating from it.
4. Explain the Regression
Testing and Integration Testing in detail.[May/June 2010]
REGRESSION TESTING:
Regression testing is testing
done to check that a system update does not re-introduce errors that have been
corrected earlier.
All – or almost all – regression
tests aim at checking the,
·
Functionality – black box tests.
·
Architecture – grey box tests
Since they are supposed to test
all functionality and all previously done changes, regression tests are usually
large.
Thus, regression testing needs
automatic,
Execution – no human
intervention
Checking. Leaving the checking
to developers will not work.
We face the same challenge when
doing automating regression test as we face when doing automatic test checking
in general:
Which parts of the output should
be checked against the oracle?
This question gets more important
as we need to have more version of the same test due to system variability.
Simple but annoying – and
sometimes expensive – problems are e.g.
Use of date in the test output
Changes in number of blanks or
line shifts
Other format changes
Changes in lead texts
Simple but annoying – and
sometimes expensive – problems are e.g.
Use of date in the test output
Changes in number of blanks or
line shifts
Other format changes
Changes in lead texts
Regression testing is a critical
part of testing, but is often overlooked. Whenever a defect gets fixed, a new
feature gets added, code gets re-factored or changed in any way, and there is
always a chance that the changes may break something, that was previously
working. Regression testing is the testing of features, functions, etc. that
have been tested before, to make sure they still work, after a change has been
made to software.
Within a set of release cycles, the flow is
typically as follows: The testers will test the software and find several
defects. The developers will fix the defects, possibly add a few more features
and give it back to be tested. The testers will then have not only tested the
new features, but test all of the old features to make sure they still work.
Questions often arise as to how much
Regression Testing needs to be done. Ideally, in Regression Testing, everything
would be tested just as thoroughly as it was the first time, but this becomes
impractical as time goes on and more and more features and, therefore, test
cases get added. When looking at which tests to execute during regression
testing, some compromises need to be made. When deciding, you will want to
focus on what has changed. If a feature has been significantly added to or
changed, then you will want to execute a lot of tests against this feature. If
a defect has been fixed in a particular area you will want to check that area
to see that the fix didn't cause new defects. If, on the other hand, a feature
has been working well for some time and hasn't been modified only a quick test
may need to be executed.
INTEGRATION TESTING:
Integration Testing,
Tests complete systems or subsystems composed
of integrated components
Integration testing should be black-box
testing with tests derived from the specification
Main difficulty is localising errors
\
Approaches to Integration
Testing:
Top-down Testing:
Start with high-level system and
integrate from the top-down replacing individual components by stubs where
appropriate.
Level 2 Level 2 Level 2 Level 2
Level 1 Level 1 Testing sequence Level 2 stubs Level 3 stubs . . .
Bottom-up Testing:
Integrate individual components
in levels until the complete system is created. Level N Level N Level N Level N
Level N Level N–1 Level N–1 Level N–1 Testing sequence Test drivers Test
drivers
In practice, most integration
involves a combination of these strategies
UNIT 5: SOFTWARE PROJECT MANAGEMENT
PART A
1. What is
software project management?
Software
project management is an umbrella activity within software engineering. It
begins before any technical activity is initiated and continues throughout the
definition, development and support of computer software.
2. Mention
the players in the software project.
The
software process is populated by players who are categorized into one of five
constituencies:
a)
Senior managers
b)
Project managers
c)
Practitioners
d)
Customers
e)
End-users
3. Mention
the activities encompassed by project management.
The
project management activity encompasses measurements and metrics, estimation,
risk analysis, schedules, tracking and control
.4. Why is measurement
necessary for software engineering?
Measurement
can be applied for a software process with the intent of improving it on a
continuous basis. It can be used thought a software project to assist in
estimation, quality control, productivity assessment and project control. It
can be used to assess the quality of technical work products and assist in
tactical decision-making as a project proceeds.
4. Define
metric.
IEEE93define
metrics as “ a quantitative measure of the degree to which a system, component
or process possesses a given attributes.
5.
Define measure and measurement.
Measure
provides a quantitative indication of the extent, amount, dimension, capacity
or size of some attribute of a product or process. Measurement is the act of
determining a measure.
6. What
are the different types of measures? Give examples.
There
are two types of measures: Direct and Indirect measures. Direct measures of the
product include line of code (LOC) produced, execution speed, memory size and
defect reported over some period of time. Indirect measures of the product
include functionality, quality, complexity, efficiency, reliability,
maintainability etc.
7. Mention the two categories of metrics.
The two categories of metrics
are Size-oriented metrics and funcation-oriended metrics.
8. What is Function-oriented metrics?
Function-oriented
metrics use a measure of the functionality delivered by application as a
normalization value.
9. What is function point? How
is it derived?
Function
Point is a function-oriented metric that is derived using an empirical
relationship based on countable (direct) measures of software’s information
domain and assessments of software complexity.
10. What is the formula for
Function Point?
To
compute Function point (FP), the following relationship is used.
FP=count
total X [0.65 +0.01x? If]
Where
count total is the sum of all FP entries
If are “complexity
adjustment values”
11. Define cyclomatic
complexity.[may/june 2011]
Cyclomatic
complexity is a software metric that provides a quantitative measure of the
logical complexity of a program.
12. What is COCOMO
model?[may/june 2013]
COCOMO,
Constructive Cost Model is a hierarchy of estimation models that addresses the
following areas:
a)
Application composition Model
b)
Early design stage model
c)
Post-architecture-stage model
COCOMO model uses different
sizing option like object points, Function points and Lines of source code.
13. What is Software project scheduling?
Software
project scheduling is an activity that distributes estimated effort across the
planned project duration by allocating the effort to specific software
engineering tasks.
14. What is Earned value Analysis?
Earned
Value Analysis is a technique for performing quantitative analysis of progress
of the software project. The earned value system provides a common value scale
for every task, regardless of the type of work being performed. Earned value is
simply a measure of progress.
15. What is Error tracking?
Error
tracking is an activity that provides a means for assessing the status of a
current project.
16. What is done during software
maintenance?
Changes
are made in response to changed requirements but the fundamental software
structure is stable. Modifying a program after it has been put into use,
Maintenance does not normally involve major changes to the system architecture.
Changes are implemented by modifying existing components and adding new
components to the system.
17. What is adaptive
maintenance?
Adaptive
maintenance is the maintenance to adapt software to a different operation
environment. It involves changing a system so that it operates in a different
environment from its initial implementation.
18. What is preventive
maintenance?
Preventive
maintenance is the maintenance to enable the software to server the needs of
its end users. It involves changing the computer programs so that they can be
more easily corrected, adapted and enhanced.
19. What are CASE tools?
Computer-Aided
software Engineering (CASE) tools assist software engineering managers and
practitioners in every activity associated with the software process. They
automate project management activities, manage all work products produced
throughout the process and assist the engineers in their analysis, desing,
coding and test work.
PART B
1. Explain
Software Cost Estimation in detail? [Nov/Dec 2010, May/June 2014]
Software productivity
Estimation techniques
Algorithmic cost modelling
Project
duration and staffing
Fundamental
estimation questions are,
SOFTWARE COST COMPONENTS
Hardware and software costs.
Travel and training costs.
Effort costs (the dominant factor in most projects)
The salaries of engineers involved in the project;
Social and insurance costs.
Effort costs must take overheads into account
Costs of building, heating, lighting.
Costs of networking and communications.
Costs of shared facilities (e.g library, staff restaurant,
etc.).
COSTING AND PRICING:
Estimates are made to discover the cost, to the
developer, of producing a software system.
There is not a simple relationship between the
development cost and the price charged to the customer.
Broader organisational, economic, political
and business considerations influence the price charged.
SOFTWARE PRODUCTIVITY:
A measure of the rate at which individual engineers
involved in software development produce software and associated documentation.
Not quality-oriented although quality assurance is a
factor in productivity assessment.
Essentially, we want to measure
useful functionality produced per time unit.
PRODUCTIVITY MEASURES:
Size related measures based on some output from the software process. This may be
lines of delivered source code, object code instructions, etc.
Function-related measures based on an estimate of the functionality of the delivered
software. Function-points are the best known of this type of measure.
Lines
of code
Estimation
techniques
Project
duration and staffing
Staffing
requirements
2. Explain Software
Configuration Management in detail?[may/june 2014]
a) Configuration Management
Planning
b) Change Managementc Version
and Release Management
d) System Building
e) CASE tools for Configuration
Management
CONFIGURATION MANAGEMENT
PLANNING:
All products of the software
process may have to be managed:
a. Specifications;
b. Designs;
c. Programs;
d. Test data;
e. User manuals.
3. Explain COCOMO Model in
detail? [Nov/Dec 2011, 2014]
COCOMO MODELS:
COCOMO has three different
models that reflect the complexity:
The Basic Model
The Intermediate Model
The Detailed Model
The Development Modes: Project
Characteristics:
Organic Mode:
Relatively small, simple
software projects
Small teams with good application experience work to a set
of less than rigid requirements
Similar to the previously developed projects
relatively small and
requires little innovation
Semidetached Mode:
Intermediate (in size and complexity) software projects in which teams
with mixed experience levels must meet a mix of rigid and less than
rigid requirements.
Embedded Mode:
Software projects that must be
developed within a set of tight hardware, software, and operational
constraints
BASIC COCOMO MODEL:
Formula:
E=ab (KLOC or KDSI) bb
D=cb (E) db
P=E/D
*-*-*-*